
The Building Blocks of Interpretability
Posted by Chris Olah, Research Scientist and Arvind Satyanarayan, Visiting Researcher, Google Brain Team
(Crossposted on the Google Open Source Blog)
In 2015, our early attempts to visualize how neural networks understand images led to psychedelic images. Soon after, we open sourced our code as DeepDream and it grew into a small art movement producing all sorts of amazing things. But we also continued the original line of research behind DeepDream, trying to address one of the most exciting questions in Deep Learning: how do neural networks do what they do?
Last year in the online journal Distill, we demonstrated how those same techniques could show what individual neurons in a network do, rather than just what is “interesting to the network” as in DeepDream. This allowed us to see how neurons in the middle of the network are detectors for all sorts of things — buttons, patches of cloth, buildings — and see how those build up to be more and more sophisticated over the networks layers.

While visualizing neurons is exciting, our work last year was missing something important: how do these neurons actually connect to what the network does in practice?
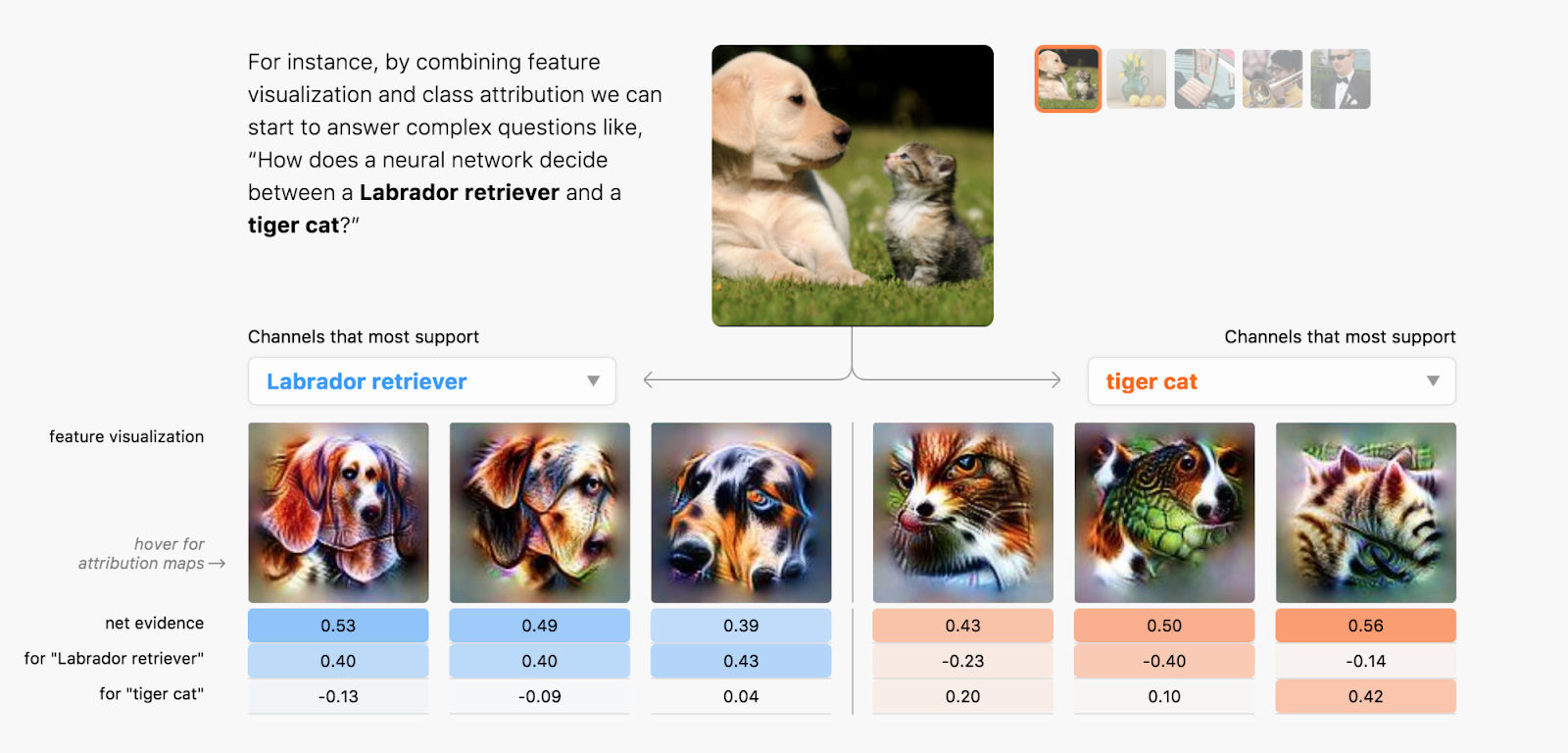
Today, we’re excited to publish “The Building Blocks of Interpretability,” a new Distill article exploring how feature visualization can combine together with other interpretability techniques to understand aspects of how networks make decisions. We show that these combinations can allow us to sort of “stand in the middle of a neural network” and see some of the decisions being made at that point, and how they influence the final output. For example, we can see things like how a network detects a floppy ear, and then that increases the probability it gives to the image being a “Labrador retriever” or “beagle”.
We explore techniques for understanding which neurons fire in the network. Normally, if we ask which neurons fire, we get something meaningless like “neuron 538 fired a little bit,” which isn’t very helpful even to experts. Our techniques make things more meaningful to humans by attaching visualizations to each neuron, so we can see things like “the floppy ear detector fired”. It’s almost a kind of MRI for neural networks.

We can also zoom out and show how the entire image was “perceived” at different layers. This allows us to really see the transition from the network detecting very simple combinations of edges, to rich textures and 3d structure, to high-level structures like ears, snouts, heads and legs.

These insights are exciting by themselves, but they become even more exciting when we can relate them to the final decision the network makes. So not only can we see that the network detected a floppy ear, but we can also see how that increases the probability of the image being a labrador retriever.
In addition to our paper, we’re also releasing Lucid, a neural network visualization library building off our work on DeepDream. It allows you to make the sort of lucid feature visualizations we see above, in addition to more artistic DeepDream images.
We’re also releasing colab notebooks. These notebooks make it extremely easy to use Lucid to reproduce visualizations in our article! Just open the notebook, click a button to run code — no setup required!

This work only scratches the surface of the kind of interfaces that we think it’s possible to build for understanding neural networks. We’re excited to see what the community will do — and we’re excited to work together towards deeper human understanding of neural networks.
I must get across my affection for your kind-heartedness for men and women that have the need for assistance with this important area of interest. Your personal commitment to getting the message all over was amazingly important and has all the time made some individuals just like me to realize their dreams. Your own informative help and advice denotes a lot to me and especially to my office workers. With thanks; from all of us.
I actually wanted to send a brief comment so as to say thanks to you for all the fantastic tips you are giving here. My extensive internet search has at the end of the day been recognized with reasonable details to talk about with my close friends. I would believe that most of us readers actually are truly lucky to live in a useful place with so many marvellous professionals with very helpful strategies. I feel rather happy to have discovered your webpage and look forward to so many more thrilling times reading here. Thank you once again for a… Read more »
I together with my pals were studying the great recommendations from the blog and the sudden developed a horrible feeling I never thanked you for those strategies. These people happened to be certainly excited to learn them and have in effect actually been enjoying them. I appreciate you for getting simply kind and for picking some quality subject areas millions of individuals are really desperate to be aware of. My personal sincere apologies for not expressing gratitude to earlier.
I wanted to create you this bit of note to be able to thank you very much over again regarding the fantastic secrets you have provided above. It’s seriously generous of you to give without restraint what exactly many people could have advertised for an electronic book to help make some bucks for their own end, most importantly considering that you might well have tried it if you considered necessary. The thoughts also served as a good way to know that other individuals have the identical passion much like my very own to find out much more in terms of… Read more »
I precisely had to appreciate you once more. I am not sure what I could possibly have undertaken without the techniques revealed by you about such a area. This was a depressing crisis for me personally, but witnessing a specialized avenue you treated it made me to cry with contentment. I am just thankful for your service and in addition expect you comprehend what a great job you are accomplishing educating some other people through your website. Most likely you’ve never encountered all of us.
I truly wanted to write a quick word to say thanks to you for some of the remarkable guidelines you are writing on this site. My particularly long internet lookup has finally been honored with reputable insight to exchange with my family and friends. I would assume that many of us readers actually are very much fortunate to be in a fabulous place with so many outstanding professionals with helpful tips and hints. I feel very much happy to have discovered your entire website and look forward to so many more fabulous times reading here. Thanks once again for everything.
I wish to express my appreciation for your kind-heartedness in support of men and women that require guidance on this important issue. Your personal dedication to passing the solution along ended up being certainly important and have truly made regular people just like me to achieve their endeavors. Your entire useful information entails a lot a person like me and substantially more to my colleagues. Thank you; from each one of us.