
DeepMind’s AI can ‘imagine’ a world based on a single picture

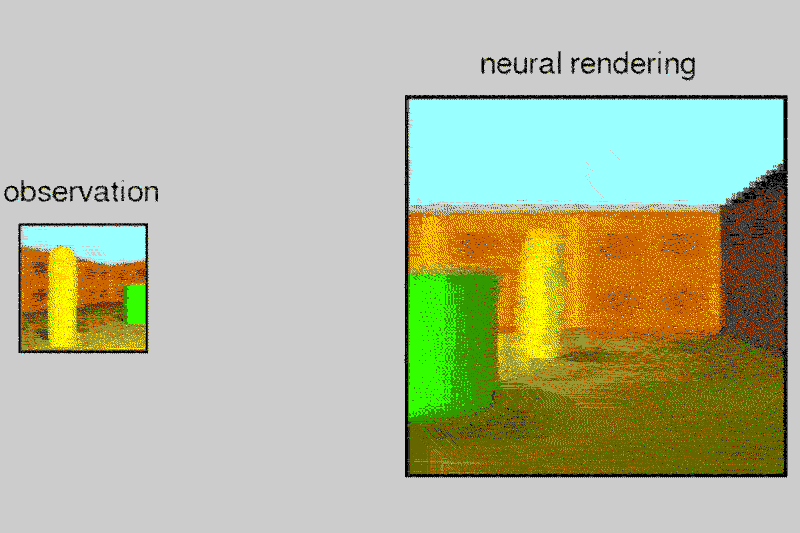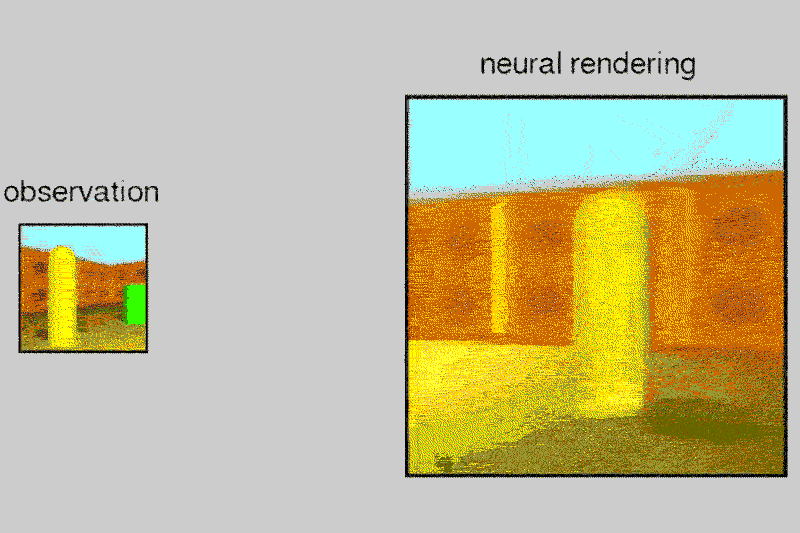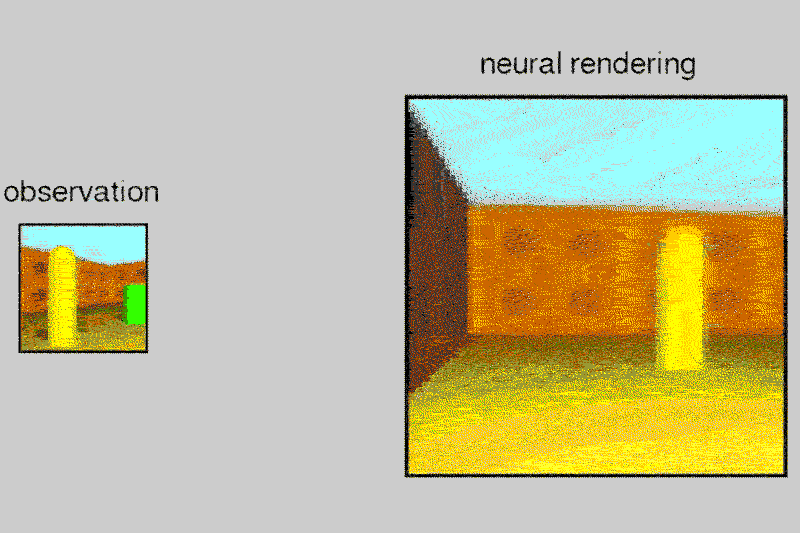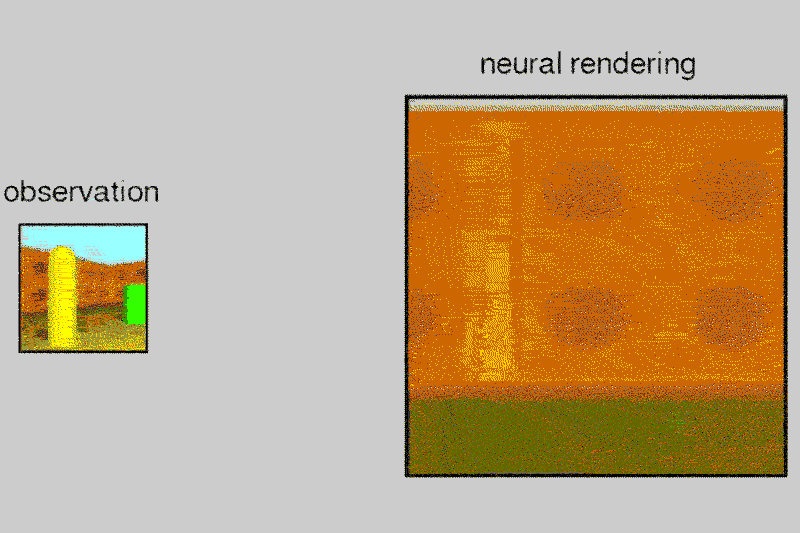
DeepMind’s AI can build up a vision of the world from multiple pictures
Udo Siebig/ALAMY
Artificial intelligence can now put itself in someone else’s shoes. DeepMind has developed a neural network that taught itself to ‘imagine’ a scene from different viewpoints, based on just a single image.
Given a 2D picture of a scene – say, a room with a brick wall, and a brightly coloured sphere and cube on the floor – the neural network can generate a 3D view from a different vantage point, rendering the opposite sides of the objects and altering where shadows fall to maintain the same light source.
The system, called the Generative Query Network (GQN), can tease out details from the static images to guess at spatial relationships, including the camera’s position.
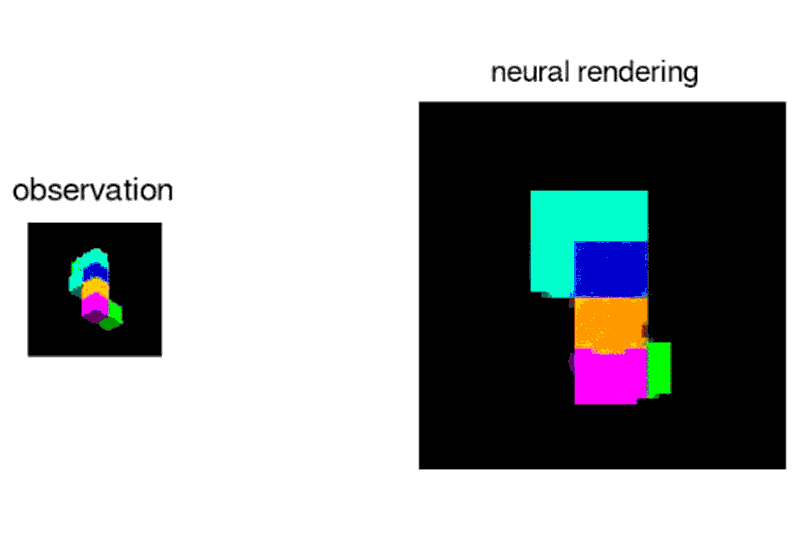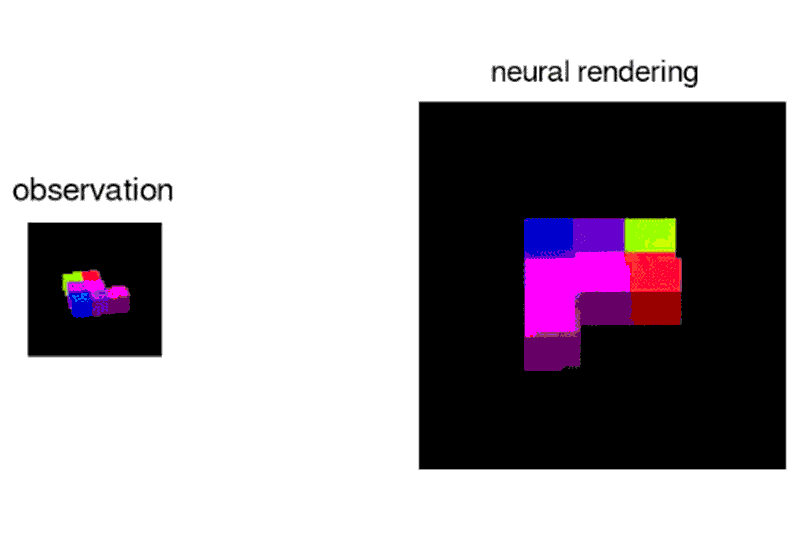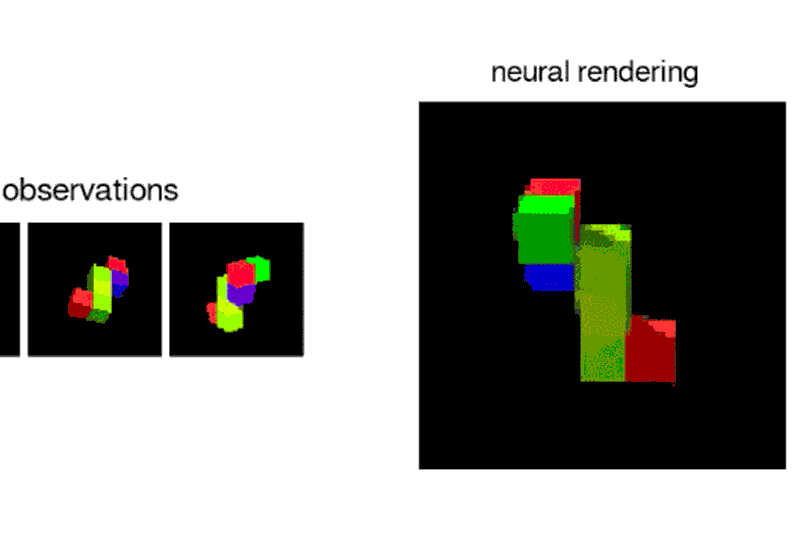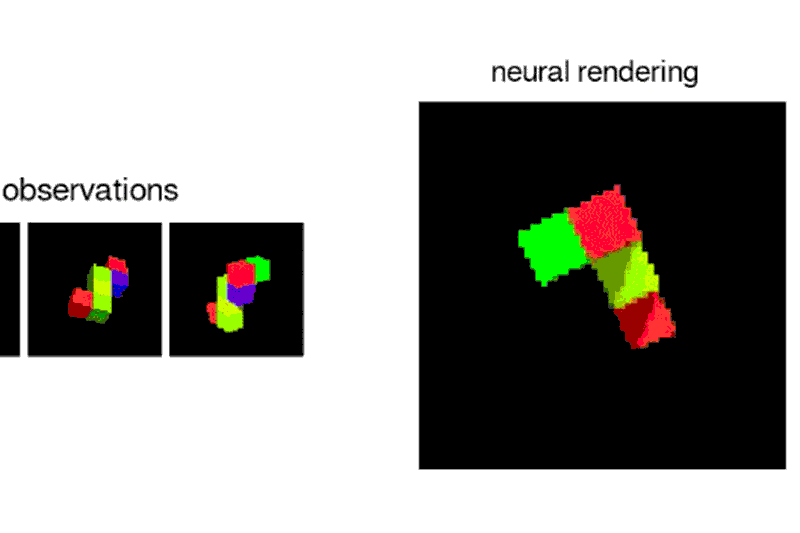
“Imagine you’re looking at Mt. Everest, and you move a metre – the mountain doesn’t change size, which tells you something about its distance from you,”says Ali Eslami who led the project at Deepmind.
“But if you look at a mug, it would change position. That’s similar to how this works,”
To train the neural network, he and his team showed it images of a scene from different viewpoints, which it used to predict what something would look like from behind or off to the side. The system also taught itself through context about textures, colours, and lighting. This is in contrast to the current technique of supervised learning, in which the details of a scene are manually labeled and fed to the AI.
The AI can also control objects in virtual space, applying its understanding of spatial relationships to a scenario where it moved a robotic arm to pick up a ball. It learns a lot like we do, even if we don’t realise it, says Danilo Rezende at DeepMind, who also worked on the project.
By showing the neural network many images in training, it can suss out the characteristics of similar objects and remember them. “If you look inside the model, we can identify groups of artificial neurons, units in the computational graph, that represent the object,” Rezende says.
The system moves around these scenes, making predictions about where things should be and what they ought to look like, and adjusting when its predictions are incorrect.
It was able to use this ability to work out the layout of a maze after seeing just a few pictures of it taken from different viewpoints.

I would like to convey my love for your kind-heartedness supporting men and women who absolutely need help with this important subject. Your special commitment to passing the solution along appears to be rather advantageous and has continuously helped others just like me to arrive at their targets. Your helpful tutorial can mean so much a person like me and much more to my office colleagues. Warm regards; from all of us.
I together with my buddies appeared to be looking through the nice solutions located on the website and then immediately I had a horrible feeling I never expressed respect to the web blog owner for those tips. All of the women are already stimulated to read through all of them and now have in actuality been using those things. Many thanks for simply being considerably helpful and then for finding varieties of very good issues millions of individuals are really desirous to know about. Our honest regret for not expressing gratitude to sooner.
My spouse and i got so ecstatic when Chris managed to deal with his studies out of the precious recommendations he received from your web site. It’s not at all simplistic to simply choose to be giving out information and facts which men and women might have been selling. And we all consider we now have the writer to thank because of that. The specific explanations you’ve made, the simple blog menu, the friendships you will make it easier to foster – it’s got many astonishing, and it’s making our son and us believe that the subject matter is enjoyable,… Read more »
I wish to show my appreciation to this writer just for bailing me out of this type of problem. After looking out through the internet and finding tips that were not pleasant, I assumed my entire life was over. Existing without the answers to the issues you’ve fixed by means of your good write-up is a serious case, and ones that would have badly affected my career if I hadn’t discovered your blog. The expertise and kindness in controlling a lot of things was very helpful. I’m not sure what I would have done if I hadn’t come across such… Read more »
I actually wanted to send a brief comment in order to thank you for all of the remarkable guides you are writing here. My time intensive internet look up has finally been paid with brilliant information to write about with my relatives. I ‘d say that we visitors actually are unquestionably lucky to live in a good website with many lovely people with very helpful guidelines. I feel extremely blessed to have seen the website and look forward to really more awesome moments reading here. Thanks once more for all the details.
I enjoy you because of each of your effort on this blog. My daughter take interest in carrying out research and it’s easy to see why. We all know all regarding the lively manner you create vital ideas through the web site and therefore inspire response from people on that issue while our own daughter is starting to learn a great deal. Enjoy the remaining portion of the new year. You are always conducting a wonderful job.
I have to get across my respect for your kind-heartedness for visitors who need help with this important issue. Your real dedication to getting the message all through appeared to be quite powerful and have truly empowered somebody much like me to arrive at their endeavors. Your amazing valuable publication indicates a whole lot to me and even more to my mates. Many thanks; from all of us.
Greetings from Florida! I’m bored to death at work so I decided to check
out your website on my iphone during lunch break. I enjoy the
knowledge you present here and can’t wait to take a look when I get home.
I’m amazed at how fast your blog loaded on my mobile ..
I’m not even using WIFI, just 3G .. Anyways, awesome blog!
We’re a gaggle of volunteers and starting
a brand new scheme in our community. Your website offered us
with useful info to work on. You have done an impressive process and our entire group shall be grateful to you.
cialis l\’espresso Viagra Oral Jelly cialis wears off https://impotencecdny.com/ – cheap prescription drugs ’