Understanding deep learning through neuron deletion
By DeepMind
Deep neural networks are composed of many individual neurons, which combine in complex and counterintuitive ways to solve a wide range of challenging tasks. This complexity grants neural networks their power but also earns them their reputation as confusing and opaque black boxes.
Understanding how deep neural networks function is critical for explaining their decisions and enabling us to build more powerful systems. For instance, imagine the difficulty of trying to build a clock without understanding how individual gears fit together. One approach to understanding neural networks, both in neuroscience and deep learning, is to investigate the role of individual neurons, especially those which are easily interpretable.
Our investigation into the importance of single directions for generalisation, soon to appear at the Sixth International Conference on Learning Representations (ICLR), uses an approach inspired by decades of experimental neuroscience — exploring the impact of damage — to determine: how important are small groups of neurons in deep neural networks? Are more easily interpretable neurons also more important to the network’s computation?
We measured the performance impact of damaging the network by deleting individual neurons as well as groups of neurons. Our experiments led to two surprising findings:
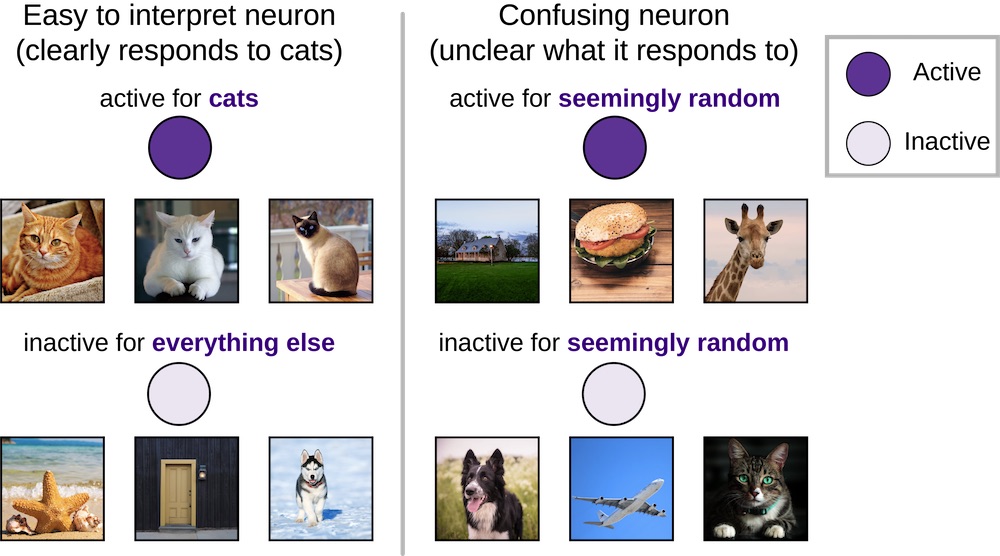
- Although many previous studies have focused on understanding easily interpretable individual neurons (e.g. “cat neurons”, or neurons in the hidden layers of deep networks which are only active in response to images of cats), we found that these interpretable neurons are no more important than confusing neurons with difficult-to-interpret activity.
- Networks which correctly classify unseen images are more resilient to neuron deletion than networks which can only classify images they have seen before. In other words, networks which generalise well are much less reliant on single directions than those which memorise.
“Cat neurons” may be more interpretable, but they’re not more important
In both neuroscience and deep learning, easily interpretable neurons (“selective” neurons) which are only active in response to images of a single input category, such as dogs, have been analysed extensively. In deep learning, this has led to the emphasis on cat neurons, sentiment neurons, and parentheses neurons; in neuroscience, Jennifer Aniston neurons, among others. However, the relative importance of these few highly selective neurons compared to the majority of neurons which have low selectivity and more puzzling, hard-to-interpret activity has remained unknown.
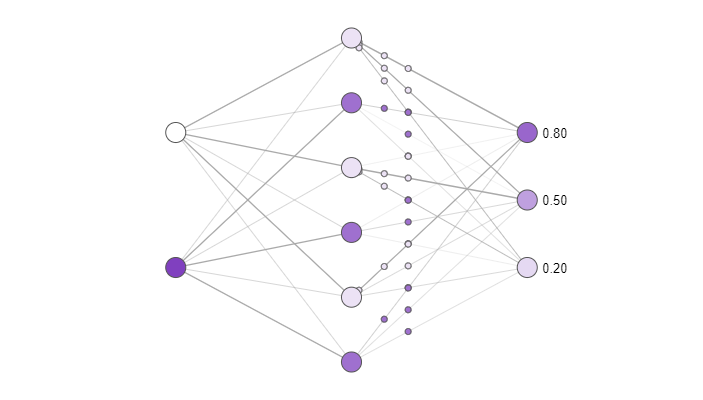
To evaluate neuron importance, we measured how network performance on image classification tasks changes when a neuron is deleted. If a neuron is very important, deleting it should be highly damaging and substantially decrease network performance, while the deletion of an unimportant neuron should have little impact. Neuroscientists routinely perform similar experiments, although they cannot achieve the fine-grained precision which is necessary for these experiments and readily available in artificial neural networks.
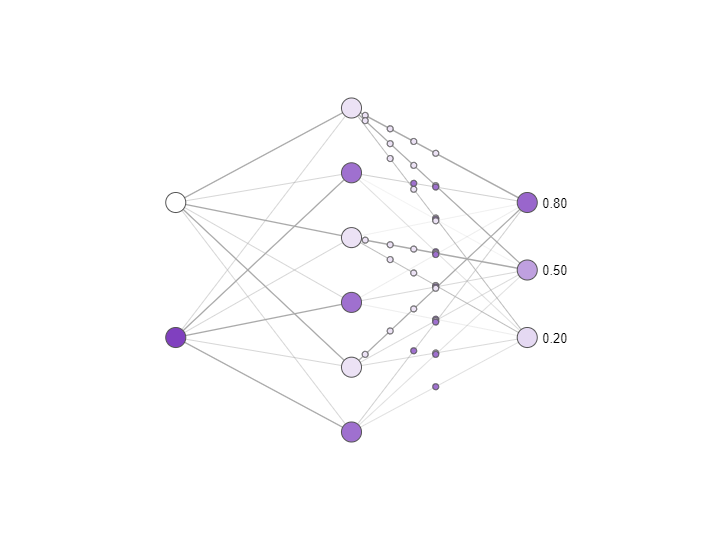
Conceptual diagram of the impact of deletion on a simple neural network. Darker neurons are more active. Try clicking hidden layer neurons to delete them and see how the activity of the output neurons changes. Notice that deleting only one or two neurons has a small impact on the output, while deleting most of the neurons has a large impact, and that some neurons are more important than others!
Surprisingly, we found that there was little relationship between selectivity and importance. In other words, “cat neurons” were no more important than confusing neurons. This finding echoes recent work in neuroscience which has demonstrated that confusing neurons can actually be quite informative, and suggests that we must look beyond the most easily interpretable neurons in order to understand deep neural networks.
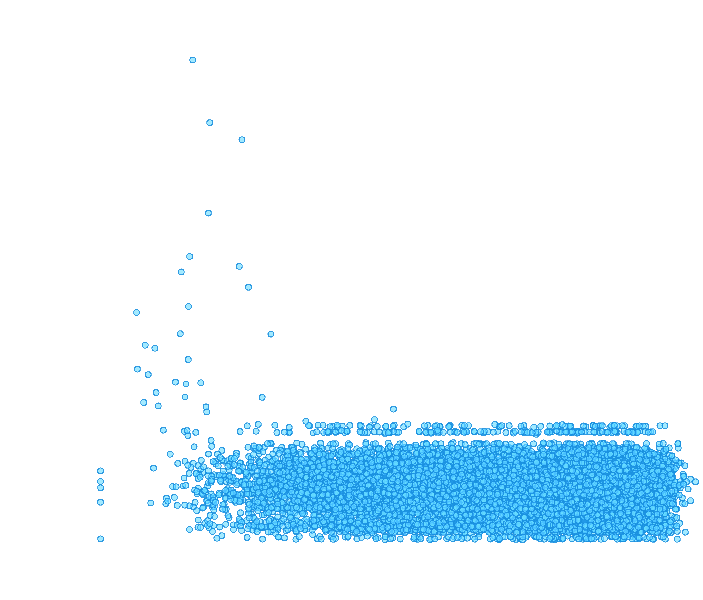
While “cat neurons” may be more interpretable, they are no more important than confusing neurons that have no obvious preference. Try clicking the plot to see what we’d expect for different relationships between importance and interpretability!
Although interpretable neurons are easier to understand intuitively (“it likes dogs”), they are no more important than confusing neurons with no obvious preference.
Networks which generalise better are harder to break
We seek to build intelligent systems, and we can only call a system intelligent if it can generalise to new situations. For example, an image classification network which can only classify specific dog images that it has seen before, but not new images of the same dog, is useless. It is only in the intelligent categorisation of new examples that these systems gain their utility. A recent collaborative paper from Google Brain, Berkeley, and DeepMind which won best paper at ICLR 2017 showed that deep nets can simply memorise each and every image on which they are trained instead of learning in a more human-like way (e.g., understanding the abstract notion of a “dog”).
However, it is often unclear whether a network has learned a solution which will generalise to new situations or not. By deleting progressively larger and larger groups of neurons, we found that networks which generalise well were much more robust to deletions than networks which simply memorised images that were previously seen during training. In other words, networks which generalise better are harder to break (although they can definitely still be broken).
By measuring network robustness in this way, we can evaluate whether a network is exploiting undesirable memorisation to “cheat.” Understanding how networks change when they memorise will help us to build new networks which memorise less and generalise more.
Neuroscience-inspired analysis
Together, these findings demonstrate the power of using techniques inspired by experimental neuroscience to understand neural networks. Using these methods, we found that highly selective individual neurons are no more important than non-selective neurons, and that networks which generalise well are much less reliant on individual neurons than those which simply memorise the training data. These results imply that individual neurons may be much less important than a first glance may suggest.
By working to explain the role of all neurons, not just those which are easy-to-interpret, we hope to better understand the inner workings of neural networks, and critically, to use this understanding to build more intelligent and general systems.
Read the full paper here.
Despite their ability to memorize large datasets, deep neural networks often achieve good generalization performance. However, the differences between the learned solutions of networks which generalize and those which do not remain unclear. Additionally, the tuning properties of single directions (defined as the activation of a single unit or some linear combination of units in response to some input) have been highlighted, but their importance has not been evaluated. Here, we connect these lines of inquiry to demonstrate that a network’s reliance on single directions is a good predictor of its generalization performance, across networks trained on datasets with different fractions of corrupted labels, across ensembles of networks trained on datasets with unmodified labels, across different hyperparameters, and over the course of training. While dropout only regularizes this quantity up to a point, batch normalization implicitly discourages single direction reliance, in part by decreasing the class selectivity of individual units. Finally, we find that class selectivity is a poor predictor of task importance, suggesting not only that networks which generalize well minimize their dependence on individual units by reducing their selectivity, but also that individually selective units may not be necessary for strong network performance.
https://arxiv.org/pdf/1803.06959.pdf
This work was done by Ari S Morcos, David GT Barrett, Neil C Rabinowitz, and Matthew Botvinick.
Visualisations were created by Paul Lewis, Adam Cain, and Doug Fritz.
Hi. I have checked your codesign.blog and i see you’ve
got some duplicate content so probably it is the reason that you
don’t rank high in google. But you can fix this
issue fast. There is a tool that creates articles like human, just search in google:
miftolo’s tools